简介
可加载内核模块,简称LKM ,是Linux内核的一个模块。通常, LKM用于添加对新硬件(作为设备驱动程序)或文件系统的支持,或者添加其他系统调用。如果没有LKM ,操作系统就必须包括所有可能预期的功能。当开发一个平台,用于智能手机以及服务器等各种设备时,这是几乎不可能做到的。LKM为内核和计算机用户提供了额外的功能,并且可以在需要或不需要时安全地添加或删除。不幸的是,这个功能可能会被滥用来创建恶意软件,即内核模式rootkit。Linux内核模式rootkit在正确执行时比大多数其他恶意软件更难检测,因为它们提供的功能会隐藏或者伪造返回的信息。因此,开发多种检测更高级rootkit的方法将有益于全球的系统管理员。
内核态Rootkits
为什么恶意软件的作者会想开发一个在内核态的Rootkit?Rootkit可以位于user-land或kernel-land中。图1详细描述了与user-land和kernel-land相关的理论特权环。User-land表示特权环3,kernel-land表示特权环0。内核负责处理用户系统的许多功能,无论是浏览本地文件还是使用Web浏览器浏览Internet。这通过实现系统调用(在内核上下文中运行的低级函数)来实现。
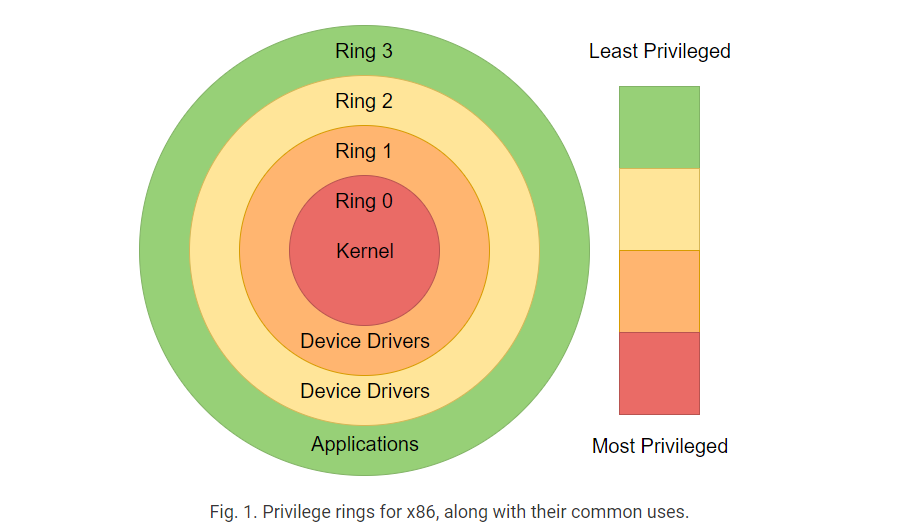
例如,像printf这样的库函数最终总是调用write来将任何信息写入您要发送到的外设。现在您可能会问,“但是如果写在内核中,我的输入如何进入内核运行代码?”在程序集中,当syscall被设置为执行时,int80指令从编译器发出。指令int 0x80触发一个可屏蔽中断,该中断将控制权从用户传送到内核(ring 3到ring 0)。为需要注意的是这不再是标准方法(现在存在SYSENTER/SYSEXIT和SYSCALL),但概念是一样的。用户希望内核处理这个调用并返回正确的结果。当rootkit成为内核的一部分时,它们能够实时修改用户收到的信息。
Rootkit常见功能
Rootkit通常具有相似的核心功能。最常见的rootkit功能包括隐藏攻击者的恶意文件、进程或网络连接、为将来的事件(后门)提供未经授权的访问、部署键盘记录程序以及删除将揭示攻击者存在的系统日志。在下一节中,我们将讨论设计内核模块rootkit函数所需的特定于实现的细节。
Rookit检测
Hidden Module
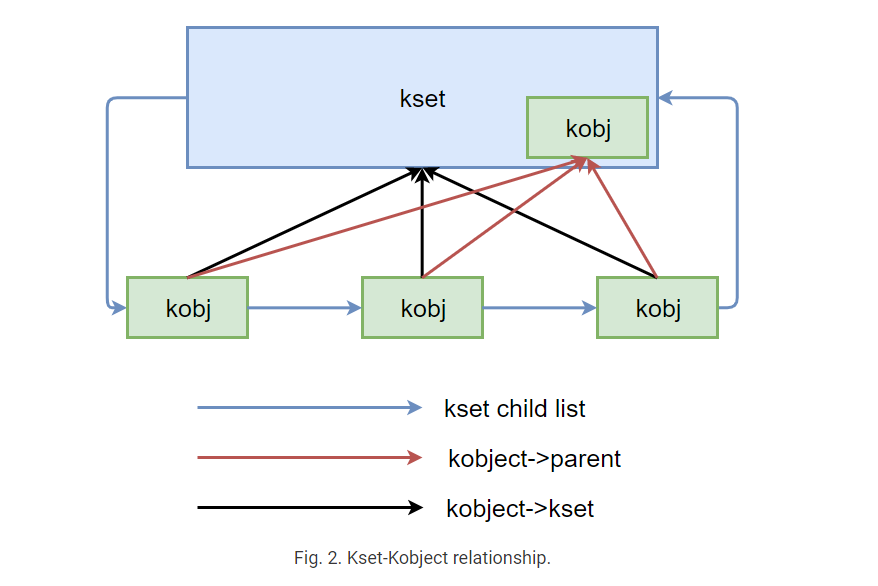
Sysfs包含许多kset(kernel sets),这些kset又包含多个kobject(kernel objects)。sysfs中的kset module_kset保存对所有加载的内核模块的kobject引用。通过遍历此列表,我们可以将每个kobject解析回其包含对象(其引用的内核模块)。与find_module(kobj->mod->name)中的当前模块列表条目相比,我们可以从列表中发现那些解除了自身链接的模块。有关ksets和kobject之间关系的更多细节,请参见图2。
查找隐藏模块伪代码
1 | list_for_each_entry_safe(cur, tmp, &mod_kset->list, entry){ |
2 | if (!kobject_name(tmp)) |
3 | break; |
4 | |
5 | kobj = container_of(tmp, struct module_kobject, kobj); |
6 | |
7 | if (kobj && kobj->mod && kobj->mod->name){ |
8 | mutex_lock(&module_mutex); |
9 | if(!find_module(kobj->mod->name)) |
10 | ALERT("Module [%s] hidden.\n", kobj->mod->name); |
11 | mutex_unlock(&module_mutex); |
12 | } |
13 | } |
Syscall/Interrupt Descriptor Table Hooking
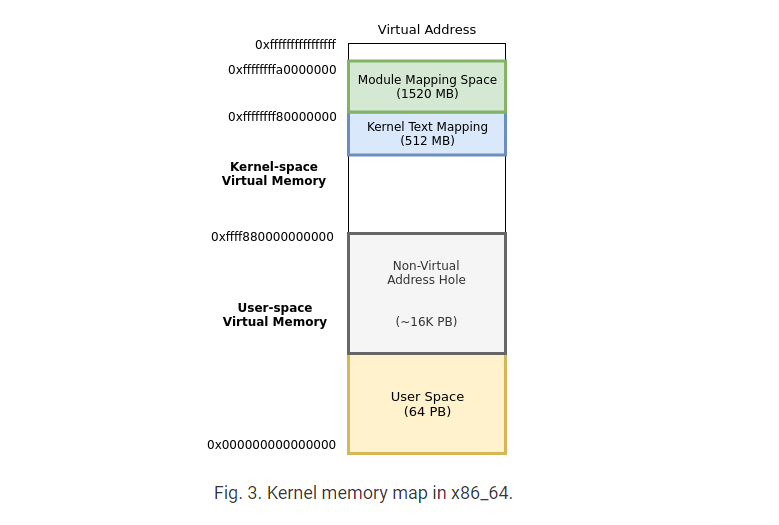
搜索syscall表,查看是否有任何函数指向kernel text section。如果它们没有指向kernel text section,那么它们很可能已经被hook,但是为了验证这一点,我们搜索所有加载的模块来验证这一点。图3描述了x86_64的内核的内存映射。可以参考这里。在这里我们可以看到内核文本映射驻留在它自己的区域中,内核模块被映射到它们正上方的空间中。使用此方法,我们可以确定函数地址所在的位置,并对其是否已挂接进行判断调用。
下面是内核用来检查地址是否位于此文本映射中的代码。_stext和_etext分别表示文本映射的开始和结束。参考这里。
1 | int notrace |
2 | core_kernel_text(unsigned long addr) |
3 | { |
4 | if (addr >= (unsigned long)_stext && addr < (unsigned long)_etext) |
5 | return 1; |
6 | |
7 | if (system_state < SYSTEM_RUNNING && init_kernel_text(addr)) |
8 | return 1; |
9 | return 0; |
10 | } |
通过迭代syscall表,并利用这个函数来验证syscall表的完整性。sct[i]表示第i个系统调用。get_module_from_addr尝试检索与hook address关联的内核模块。如果返回NULL,则隐藏该模块。在这种情况下,我们使用另一种方法来解析隐藏模块。
1 | for (i = 0; i < NR_syscalls; i++){ |
2 | addr = sct[i]; |
3 | if (!ckt(addr)){ |
4 | mutex_lock(&module_mutex); |
5 | mod = get_module_from_addr(addr); |
6 | if (mod){ |
7 | ALERT("Module [%s] hooked syscall [%d].\n", mod->name, i); |
8 | } else { |
9 | mod_name = find_hidden_module(addr); |
10 | if (mod_name) |
11 | ALERT("Hidden module [%s] hooked syscall [%d].\n", mod_name, i); |
12 | } |
13 | mutex_unlock(&module_mutex); |
14 | } |
15 | } |
Netfilter Hooking
搜索所有可能的Netfilter hook组合,并报告所有具有活动Netfilter hook的模块。Netfilter钩子有合法用途,但是它们不可能出现在iptables、ebtables和friends之外。它们通常用于内核模式的rootkit中,通过截获用于端口验证身份验证的数据包来创建后门。如果您想了解更多关于在内核中实现Netfilter钩子的信息,可以参考这里。
涉及的代码相当繁琐,因为Netfilter函数最近经常更改。访问此信息的另一个问题是没有友好的API。例如,以下所有三个代码块都执行相同的操作-在netfilter hook数组上迭代。
对于内核版本≥ 4.14 ,我们可以窃取nf_hook_entry_head函数,因为将来的函数依赖于相同的原型,它将返回struct nf_hook_entries ,直到4.19 (到目前为止)为止。
1 | static struct nf_hook_entries __rcu ** |
2 | nf_hook_entry_head(struct net *net, int pf, unsigned int hooknum, struct net_device *dev) |
3 | { |
4 | if (pf != NFPROTO_NETDEV) |
5 | return net->nf.hooks[pf]+hooknum; |
6 | if (hooknum == NF_NETDEV_INGRESS){ |
7 | if (dev && dev_net(dev) == net) |
8 | return &dev->nf_hooks_ingress; |
9 | } |
10 | return NULL; |
11 | } |
12 | |
13 | int analyze_netfilter(void) |
14 | { |
15 | int i, j; |
16 | struct nf_hook_entries *p; |
17 | struct nf_hook_entries __rcu **pp; |
18 | |
19 | for (i = 0; i < NFPROTO_NUMPROTO; i++){ |
20 | for (j = 0; j < NF_MAX_HOOKS; j++){ |
21 | pp = nf_hook_entry_head(&init_net, i, j, NULL); |
22 | if (!pp) |
23 | return -EINVAL; |
24 | |
25 | p = nf_entry_dereference(*pp); |
26 | if (!p) |
27 | continue; |
28 | |
29 | search_hooks(p); |
30 | } |
31 | } |
32 | |
33 | return 0; |
34 | } |
内核版本< 4.14,则没有struct nf_hook_entries。我们必须使用内核的内置列表机制struct list_head。这意味着,我们的差异不会仅仅停留在对netfilter挂接进行迭代上,而是继续研究我们如何访问这些数据。
1 | static struct nf_hook_entries __rcu ** |
2 | nf_hook_entry_head(struct net *net, int pf, unsigned int hooknum, struct net_device *dev) |
3 | { |
4 | if (pf != NFPROTO_NETDEV) |
5 | return net->nf.hooks[pf]+hooknum; |
6 | if (hooknum == NF_NETDEV_INGRESS){ |
7 | if (dev && dev_net(dev) == net) |
8 | return &dev->nf_hooks_ingress; |
9 | } |
10 | return NULL; |
11 | } |
12 | |
13 | int |
14 | analyze_netfilter(void) |
15 | { |
16 | int i, j; |
17 | struct nf_hook_entries *p; |
18 | struct nf_hook_entries __rcu **pp; |
19 | |
20 | for (i = 0; i < NFPROTO_NUMPROTO; i++){ |
21 | for (j = 0; j < NF_MAX_HOOKS; j++){ |
22 | pp = nf_hook_entry_head(&init_net, i, j, NULL); |
23 | if (!pp) |
24 | return -EINVAL; |
25 | |
26 | p = nf_entry_dereference(*pp); |
27 | if (!p) |
28 | continue; |
29 | |
30 | search_hooks(p); |
31 | } |
32 | } |
33 | |
34 | return 0; |
35 | } |
现在,我们仍然有两个访问它们的权限,这需要更多内核版本特定的代码。这就是支持多个内核版本的成本。 对于≥ 4.14,我们需要迭代一个struct nf_hook_entries *。这很简单,因为结构体内部是一个称为num_hook_entries的整数。然后,我们可以使用同一结构内的钩子数组来获取每个钩子的地址,并对照 kernel text mapping检查它。
1 | static void |
2 | search_hooks(const struct nf_hook_entries *e) |
3 | { |
4 | int i; |
5 | const char *mod_name; |
6 | unsigned long addr; |
7 | struct module *mod; |
8 | |
9 | for (i = 0; i < e->num_hook_entries; i++){ |
10 | addr = (unsigned long)e->hooks[i].hook; |
11 | mutex_lock(&module_mutex); |
12 | mod = get_module_from_addr(addr); |
13 | if (mod){ |
14 | ALERT("Module [%s] controls a Netfilter hook.\n", mod->name); |
15 | } else { |
16 | mod_name = find_hidden_module(addr); |
17 | ALERT("Module [%s] controls a Netfilter hook.\n", mod_name); |
18 | } |
19 | mutex_unlock(&module_mutex); |
20 | } |
21 | } |
对于< 4.14,我们需要迭代内核列表。这可以通过list_for_each_entry或list_for_each_entry_safe完成。
1 | static void |
2 | search_hooks(const struct list_head *hook_list) |
3 | { |
4 | const char *mod_name; |
5 | unsigned long addr; |
6 | struct module *mod; |
7 | struct nf_hook_ops *elem; |
8 | |
9 | list_for_each_entry(elem, hook_list, list){ |
10 | addr = (unsigned long)elem->hook; |
11 | mutex_lock(&module_mutex); |
12 | mod = get_module_from_addr(addr); |
13 | if (mod){ |
14 | ALERT("Module [%s] controls a Netfilter hook.\n", mod->name); |
15 | } else { |
16 | mod_name = find_hidden_module(addr); |
17 | ALERT("Module [%s] controls a Netfilter hook.\n", mod_name); |
18 | } |
19 | mutex_unlock(&module_mutex); |
20 | } |
21 | } |
Network Protocol Hooking
通过抓取init_net.proc_net进程目录条目(在您的文件系统上,这相当于/proc/net/),并遍历红黑树中的每个子目录,查找名为tcp的子目录tcp6、udp、udp6、udplite和udplite6。一旦我们获取了特定网络协议的目录条目,就可以获取seq_fops和seq_ops的函数指针,即我们正在寻找seq_fops->llseek, seq_fops->read, seq_fops->release和seq_ops->show。这样做,我们可以验证网络协议的操作函数指针仍然在core kernel text section,而不是被 kernel module操作。这些端口通常被hook,以隐藏网络流量或暴露的端口,使其不被netstat和其他用户接口使用。
为了迭代多个接口并检查相同的操作,我设计了一个简单的结构net_entry。此结构保存我们正在搜索的条目的名称,一旦找到,则保存/proc目录条目。
1 | struct net_entry { |
2 | const char *name; |
3 | struct proc_dir_entry *entry; |
4 | }; |
5 | |
6 | struct net_entry net[NUM_NET_ENTRIES] = { |
7 | {"tcp", NULL}, |
8 | {"tcp6", NULL}, |
9 | {"udp", NULL}, |
10 | {"udp6", NULL}, |
11 | {"udplite", NULL}, |
12 | {"udplite6", NULL} |
13 | }; |
下面的代码在红黑树上迭代(在本例中为/proc/net的rb-tree),并搜索具有目标字符串名称的条目。我们可以使用它来找到我们的目标net entry,并分配相应的struct proc_dir_entry。
1 | struct proc_dir_entry * |
2 | find_subdir(struct rb_root *tree, const char *str) |
3 | { |
4 | struct rb_node *node = rb_first(tree); |
5 | struct proc_dir_entry *e = NULL; |
6 | |
7 | while (node){ |
8 | e = rb_entry(node, struct proc_dir_entry, subdir_node); |
9 | if (strcmp(e->name, str) == 0) |
10 | return e; |
11 | node = rb_next(node); |
12 | } |
13 | |
14 | return NULL; |
15 | } |
现在我们可以遍历每个net entry并获取它们的seq_ops和seq_fops。
1 | unsigned long op_addr[4]; |
2 | const struct seq_operations *seq_ops; |
3 | const struct file_operations *seq_fops; |
4 | const char *mod_name, *op_string[4] = { |
5 | "llseek", "read", "release", "show" |
6 | }; |
7 | |
8 | for (i = 0; i < NUM_NET_ENTRIES; i++){ |
9 | net[i].entry = find_subdir(&init_net.proc_net->subdir, net[i].name); |
10 | if (!net[i].entry) |
11 | continue; |
12 | |
13 | seq_ops = net[i].entry->seq_ops; |
14 | seq_fops = net[i].entry->proc_fops; |
15 | |
16 | op_addr[0] = *(unsigned long *)seq_fops->llseek; |
17 | op_addr[1] = *(unsigned long *)seq_fops->read; |
18 | op_addr[2] = *(unsigned long *)seq_fops->release; |
19 | op_addr[3] = *(unsigned long *)seq_ops->show; |
20 | |
21 | /* Code to check if all of op_addr is in kernel text mapping */ |
22 | } |
Process File Operations Hooking
通过打开/proc文件指针,并检查是否有文件操作(即iterate)指向 core kernel text section。这个文件指针可以被一个rootkit hook,通过检查每个目录项和它想要隐藏的进程列表来隐藏恶意进程。如果它找到一个目录项,它就可以简单地跳过该目录项,就好像它从未存在过,导致它不会被报告回用户。
下面的代码创建一个指向/proc的文件指针,并检查iterate或readdir是否已由模块hook。
1 | fp = filp_open("/proc", O_RDONLY, S_IRUSR); |
2 | |
3 | |
4 | addr = (unsigned long)fp->f_op->iterate; |
5 | |
6 | addr = (unsigned long)fp->f_op->readdir; |
7 | |
8 | |
9 | if (!ckt(addr)){ |
10 | mod = get_module_from_addr(addr); |
11 | if (mod){ |
12 | ALERT("Module [%s] hijacked /proc fops.\n", mod->name); |
13 | } ... |
14 | } |
Zeroed Process Inodes
通过/proc搜索所有linux_dirent结构,并检查inode ,以找到任何设置为零的设置。目录清单中通常忽略一个为零的inode,这使得它成为rootkits将目录设置为以隐藏其文件的良好候选对象。
下面的代码在linux_dirent结构(本质上是一个1-D数组)上迭代,以查找inode为0的任何目录条目。图中未显示的是一个自定义的filldir函数,它是填充linux_dirent结构所必需的。这虽然具有挑战性/令人讨厌,但对理解检测并不重要。
1 | while (size > 0){ |
2 | if (d->d_ino == 0){ |
3 | buffer = kzalloc(d->d_namlen+1, GFP_KERNEL); |
4 | memcpy(buffer, d->d_name, d->d_namlen); |
5 | ALERT("Hidden Process [/proc/%s].\n", buffer); |
6 | kfree(buffer); |
7 | } |
8 | reclen = ALIGN(sizeof(*d) + d->d_namlen, sizeof(u64)); |
9 | d = (struct linux_dirent *)((char *)d + reclen); |
10 | size -= reclen; |
11 | } |
总结
1.隐藏模块的检测是通比较kobject和find_module的模块。
2.其他模块的检测都是通过找相应操作函数的地址,判断地址是否在 kernel text section来判断是否被劫持。
参考:
https://www.freebuf.com/articles/system/54263.html
https://github.com/EBWi11/AgentSmith-HIDS/blob/master/doc/AgentSmith-HIDS-Quick-Start-zh_CN.md
https://github.com/nbulischeck/tyton
https://blog.csdn.net/jasonchen_gbd/article/details/78013643
https://www.freebuf.com/articles/system/54263.html
